SSRF
介绍
SSRF 是一种由攻击者构造形成并由服务端发起恶意请求的一个安全漏洞,正是因为恶意请求是由服务器发起的,我们就可以利用此来访问服务器可以访问的内部网络系统,所以一般情况下,SSRF 攻击目标都是攻击者无法直接访问的内网系统。
如下图所示,服务器Ubuntu为WEB服务器,可被攻击者访问,内网中的其他服务器无法被攻击者直接访问。假设服务器Ubuntu中的某个WEB应用存在SSRF漏洞,那我们就可以操作这个WEB服务器去读取本地的文件、探测内网主机存活、探测内网主机端口等,如果借助相关网络协议,我们还可以攻击内网中的Redis、MySql、FastCGI等应用,WEB服务器在整个攻击过程中被作为中间人进行利用。
原因
服务端提供了从其他服务器应用获取数据的功能,但是没有对目标地址进行限制和过滤。例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片,下载等,利用的就是服务端请求伪造,SSRF漏洞可以利用存在缺陷的WEB应用作为代理攻击远程和本地的服务器。
寻找
在地址栏的参数中使用完整的 URL 时

表单中的隐藏字段
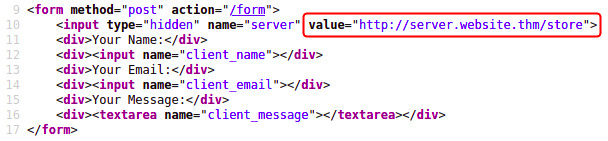
部分 URL 地址,eg: server

URL 的路径

危害
对外网、服务器所在内网、服务器本地进行端口扫描,获取一些服务的banner信息等。
攻击运行在内网或服务器本地的其他应用程序,如redis、mysql等。
对内网Web应用进行指纹识别,识别企业内部的资产信息。
攻击内外网的Web应用,主要是使用HTTP GET/POST请求就可以实现的攻击,如sql注入、文件上传等。
利用file协议读取服务器本地文件等。
进行跳板攻击等。
攻击
1. 针对服务器本身的 SSRF 攻击
攻击者通过诱导应用程序通过其环回网络接口向托管应用程序的服务器发出 HTTP 请求
服务器将会获取 /admin 的内容返回给用户
为什么应用程序会以这种方式运行,并且隐含的信任来自本地机器的请求?
访问控制检查,在应用程序服务器的不同组件中实现,当连接返回到服务器本身时,将绕过检查
出于灾难恢复的目的,应用程序可能允许来自本地计算机中的任何用户无需登陆即可进行管理访问
管理界面可能侦听与主应用程序不同的端口号,因此用户可能无法直接访问
2. 针对其他后端系统的 SSRF 攻击
服务器端请求伪造经常出现的另一种信任关系是应用程序服务器能够与用户无法直接访问的其他后端系统进行交互。这些系统通常具有不可路由的私有 IP 地址。由于后端系统通常受到网络拓扑的保护,因此它们的安全状况通常较弱。在许多情况下,内部后端系统包含敏感功能,任何能够与系统交互的人无需身份验证即可访问这些功能。
3. 盲 SSRF 漏洞
建议查看原文--> 链接
当可以诱导应用程序向提供的 URL 发出后端 HTTP 请求,但
后端请求的响应未在应用程序的前端响应中返回时,就会出现盲目 SSRF 漏洞。盲目 SSRF 通常更难利用,但有时会导致在服务器或其他后端组件上完全远程执行代码。
1. 影响
由于单向性,盲目 SSRF 漏洞的影响通常低于完全知情的 SSRF 漏洞。不能轻易利用它们从后端系统检索敏感数据,尽管在某些情况下可以利用它们来实现完全远程代码执行。
4. 读取服务器文件
5. 探测内网存活主机 (http/s 协议)
6. 扫描内网端口(http/s和dict协议)
绕过
1. 基于黑名单的输入过滤器的 SSRF
某些应用程序会阻止包含主机名(如127.0.0.1和localhost)或敏感 URL(如/admin. 在这种情况下,您通常可以使用各种技术来绕过过滤器
使用 的替代 IP 表示形式
127.0.0.1,例如2130706433、017700000001或127.1。注册您自己的解析为
127.0.0.1. 您可以spoofed.burpcollaborator.net用于此目的。使用 URL 编码或大小写变体混淆被阻止的字符串。
2. 基于白名单的输入过滤器的 SSRF
一些应用程序只允许输入匹配、开头或包含允许值的白名单。在这种情况下,您有时可以利用 URL 解析中的不一致来绕过过滤器。
@您可以使用字符 在主机名之前的 URL 中嵌入凭据。例如:您可以使用该
#字符来指示 URL 片段。例如:您可以利用 DNS 命名层次结构将所需输入放入您控制的完全限定 DNS 名称中。例如:
例如参数中使用的 URL 必须以 https://website.thm 开头的规则。 攻击者可以通过在攻击者的域名上创建子域来快速规避此规则,例如 https://website.thm.attackers-domain.thm。应用程序逻辑现在将允许此输入并让攻击者控制内部HTTP请求。
您可以对字符进行 URL 编码以混淆 URL 解析代码。如果实现过滤器的代码处理 URL 编码字符的方式与执行后端 HTTP 请求的代码不同,这将特别有用。
您可以结合使用这些技术。
3. 通过开放重定向绕过 SSRF 过滤器
有时可以通过利用开放重定向漏洞来规避任何类型的基于过滤器的防御。
在前面的 SSRF 示例中,假设用户提交的 URL 被严格验证以防止恶意利用 SSRF 行为。但是,允许使用 URL 的应用程序存在开放重定向漏洞。如果用于发出后端 HTTP 请求的 API 支持重定向,您可以构建一个满足过滤器的 URL,并将请求重定向到所需的后端目标。
例如,假设应用程序包含一个开放重定向漏洞,其中包含以下 URL:
返回重定向到:
可以利用开放重定向漏洞绕过URL过滤,利用SSRF漏洞,方法如下:
此 SSRF 漏洞利用之所以有效,是因为应用程序首先验证提供的
stockAPIURL 是否位于允许的域中,而事实确实如此。然后应用程序请求提供的 URL,这会触发打开重定向。它遵循重定向,并向攻击者选择的内部 URL 发出请求。
4. 短地址绕过
直接使用生成的短连接 https://4m.cn/FjOdQ就会自动302跳转到 http://127.0.0.1/flag.php上,这样就可以绕过WAF了:
5. 利用不存在的协议绕过指定协议头
file_get_contents()函数的一个特性,即当PHP的file_get_contents()函数在遇到不认识的协议头时候会将这个协议头当做文件夹,造成目录穿越漏洞,这时候只需不断往上跳转目录即可读到根目录的文件。(include()函数也有类似的特性)
6. URL 解析问题
该思路来自Orange Tsai成员在2017 BlackHat 美国黑客大会上做的题为《A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages》的分享。主要是利用readfile和parse_url函数的解析差异以及curl和parse_url解析差异来进行绕过。
1. 利用readfile和parse_url函数的解析差异绕过指定的端口
上述代码限制了我们传过去的url只能是80端口的,但如果我们想去读取11211端口的文件的话,我们可以用以下方法绕过:
从上图中可以看出readfile()函数获取的端口是最后冒号前面的一部分(11211),而parse_url()函数获取的则是最后冒号后面的的端口(80),利用这种差异的不同,从而绕过WAF。
这两个函数在解析host的时候也有差异,如下图:
readfile()函数获取的是@号后面一部分(evil.com),而parse_url()函数获取的则是@号前面的一部分(google.com),利用这种差异的不同,我们可以绕过题目中parse_url()函数对指定host的限制。
2. 利用curl和parse_url的解析差异绕指定的host
从上图中可以看到curl()函数解析的是第一个@后面的网址,而parse_url()函数解析的是第二个@后面的网址。利用这个原理我们可以绕过题目中parse_url()函数对指定host的限制。
上述代码中可以看到
check_inner_ip函数通过url_parse()函数检测是否为内网IP,如果不是内网 IP ,则通过curl()请求 url 并返回结果,我们可以利用curl和parse_url解析的差异不同来绕过这里的限制,让parse_url()处理外部网站网址,最后curl()请求内网网址。paylaod如下:
防御
禁用不需要的协议(如:
file:///、gopher://,dict://等)。仅仅允许http和https请求统一错误信息,防止根据错误信息判断端口状态
禁止302跳转,或每次跳转,都检查新的Host是否是内网IP,直到抵达最后的网址
设置URL白名单或者限制内网IP
参考
最后更新于